A rather simple, but effective and easy-to-setup service discovery (SD) mechanism with near-zero maintenance costs can be build by utilizing the AWS Private Hosted Zone (PHZ) feature. PHZs allows you to connect a Route53 Hosted Zone to a VPC, which in turn means that DNS records in that zone are only visible to attached VPCs.
Before digging deeper into the topic, let’s try to find a definition for ‘simple service discovery’. I’d say in 99% of the cases service discovery is something like “I am an application called myapp, please give me (for example) my database and cache endpoints, and service Y which I rely on”, so the service consumer and service announcer need to speak a common language, and we need no manual human interaction. This is at least how Wikipedia defines service discovery protocols:
Service discovery protocols (SDP) are network protocols which allow automatic detection of devices and services offered by these devices on a computer network. Service discovery requires a common language to allow software agents to make use of one another’s services without the need for continuous user intervention.
**So back to the topic. You might think: Why not use Consul, Etcd, SkyDNS etcpp? **
“no software is better than no software” — rtomayko
You are not done with installing the software. You might need to package, configure, monitor, upgrade and sometimes deeply understand and debug it as well. I for one just simply love it when my service providers are doing this for me (and Route53 has actually a very good uptime SLA, beat that!) and I can concentrate on adding value for my customers.
This is another point. Keeping it simple is hard and an art. I learned the hard way that I should try to avoid more complex tools and processes as long as possible. Once you introduced complexity it’s hard to remove it again because you or other people might have built even more complex stuff upon it.
Ok, we are almost done with my ‘Total cost of ownership’ preaching. Another aspect for me of keeping it simple and lean is to use as much infrastructure as possible from my IaaS provider. For example databases (RDS), caches (ElastiCache), Queues and storage (e.g. S3). Those services usually don’t have a native interface to announce their services to Consul, Etcd etc. so one would need to write some glue which takes events from your IaaS provider, filters and then announces changes to the SD cluster.1
Ok, so how can we achieve a service discovery with the AWS building blocks and especially Private Hosted Zones?
The first thing to do is to create a new Private Hosted Zone and associate it to your VPC. In our example we’ll call it snakeoil.prod.internal, indicating that it is the internal DNS for our snakeoil company in our environment prod (which indicates that other environments, e. g. staging or development reside in other VPCs).
Ok, nothing really special. Now we could add our first resource record to the hosted zone, and resolve it, e.g. cache-myapp, indicating it’s the cache endpoint for my appmypp. We will use CloudFormation and troposphere as a preprocessor for creating an Elasticache Cluster and its PHZ announcement:
PrivateHostedZone = "snakeoil.prod.internal."
app_elasticache = elasticache.CacheCluster(...);
template.add_resource(app_elasticache)
app_elasticache_private_hosted_zone_dns_rr = route53.RecordSetType(
"SessionClusterPHZEndpoint",
HostedZoneName=PrivateHostedZone,
Name="cache-myapp.%s" % (PrivateHostedZone),
Type="CNAME",
ResourceRecords=[Join("", [GetAtt(app_elasticache, "ConfigurationEndpoint.Address"), "."])],
TTL="60"
)
template.add_resource(app_elasticache_private_hosted_zone_dns_rr)
This snippet creates a CNAME in the PHZ which points to the ElastiCache cluster endpoint.
It will actually look like this when we ping it from an EC2 instance within the VPC:
$ host cache-myapp.prod.snakeoil.internal
cache-myapp.prod.snakeoil.internal is an alias for app-x.z7iqq9.cfg.use1.cache.amazonaws.com
app-x.z7iqq9.cfg.use1.cache.amazonaws.com has address 192.0.2.1
But wait, now we need to specify the entire PHZ domain (snakeoil.prod.internal) everytime we want to lookup the service? Wouldn’t it be great when we could just lookupcache-myapp, so our application does not need to know in which zone or environment it is running (The principle of least knowledge)?!
This is where DHCP option sets come into play. We can just create a new one which includes snakeoil.prod.internal:
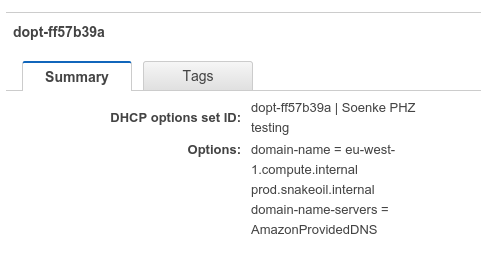
Once we associated our VPC with this DHCP option set, we can omit the domain part as it’s now part of the search domain (propagated via DHCP):
$ host cache-myapp
cache-myapp is an alias for app-x.z7iqq9.cfg.use1.cache.amazonaws.com.
app-x.z7iqq9.cfg.use1.cache.amazonaws.com has address 192.0.2.1
Now we can just hardcode the service endpoint in our software (or it’s configuration), for example like this:
$client = new Memcached();
$client->addServer('cache-myapp', $server_port);
No need for configuration management like Puppet or Chef , no need for Service Discovery (Consul etc)., and no need for glue software (e.g. confd). The contract between the service consumer and announcer is
the service name.
Hint: We could theoretically add even more granularity by creating a VPC for every (application-env)-tuple we have. This would eventually lead to a scheme where the app would only need to lookup database, cache and service-y, so even the name of the app could be omitted in the ‘search query’. But the VPC networking overhead might not be worth it. You have to decide which trade-off to make.
Warning 1: Route53 propagation times
During my research I found out that it takes approximately 40 seconds for Route53 to propagate changes. So if you rely on real-time changes, you should rather look into more sophisticated approaches like Consul, Etcd, SkyDNS etc. I guess AWS will improve propagation delays over time.
Another issue is the default SOA TTL set by AWS, it’s 900 seconds by default which actually is the negative cache TTL. That means once you requested a record which is currently not propagated, you have to wait 15 minutes until the
negative cache expires. I would recommend to set it to a low value like 10-60 seconds.
Warning 2: DNS and Networking
**”Everything is a Freaking DNS problem” **—Kris Buytaert
DNS is a network protocol and as result is constrained by the fallacies of distributed computing. DNS queries are usually not cached on Linux distros by default, but luckily there are caching solutions available. We are currently using nscd, but there is at least dnsmasq. I would recommend to install one of those to make your system more resilient in case of networking or DNS problems.
Recap
Service Discovery can be made arbitrarily complex, but it can also be kept simple using the building blocks AWS is giving us. The demonstrated pattern can be used for almost everything which just connects to an endpoint.
I am planning to write follow up blog posts for more sophisticated service discovery with SRV records, and also how to use TXT records for storing configuration/credentials, and even feature-ramp-ups within the PHZ. Stay tuned!
Acknowledgement
The basic idea of doing discovery by just resolving bare hostnames was initially brought to me by my fellow co-worker Ingo Oeser who successfully used this kind of discovery at his former employer.
He pointed out that those setups included DNSSEC as well in order to prevent DHCP and/or DNS spoofing. We currently don’t consider this a problem in an AWS VPC.
1It looks like HashiCorp can integrate IaaS components with their Autodiscovery by using their pay product ‘Atlas” as a bridge between TerraForm and Consul but I didn’t validate this hypothesis.
Like what you read?
You can hire me or make a donation via PayPal!